 I want to thank Dr. Frank Lowney from the Digital Innovation Group at Georgia College & State University for this informative guest post.
I want to thank Dr. Frank Lowney from the Digital Innovation Group at Georgia College & State University for this informative guest post.
If you’re interested in captioning your videos, you’ll find this interesting. A useful, more advanced workflow, Dr. Lowney describes how to use the Enhanced Dictation feature in MacOS X 10.9 (Mavericks), combined with Audio Hijack and Soundflower to turn recorded audio into a text file. This can be extremely handy for anyone that needs to create captions for a video, but lacks the transcribed text. Without further ado….
***
By Dr. Frank Lowney
The pressure is on to to make screencasts and other online video more accessible. One important aspect of that challenge is to make video more accessible to persons who are deaf or have difficulty hearing. For video content creators, this means providing a transcript or, better, providing subtitles to that video so that dialogue may be viewed in the same context as the video.
The problem is that many videos are created without a script that is followed closely by the speakers in that video. Indeed, many important videos are created in ad hoc fashion (interviews, panel discussions, conference presentations and the like) where scripts would be totally inappropriate.
Creating text from speech has become essential to meeting these expectations, especially where all one has to work with is the speech in the audio track of a video. Speech to text (STT) is a bit more difficult than text to speech (TTS) which has been in use much longer.
MacOS X recently introduced Dictation (speech-to-text) as a feature usable in any application that takes text as input. This is quite an advance over having to purchase a two hundred dollar application to accomplish the same end. However, the first iteration of this system required an internet connection so that speech could be uploaded to Apple’s servers where it would be turned into text. This created delays and was difficult to use for substantial bodies of text. However, Dictation was given a significant boost in MacOS X 10.9 (Mavericks) with the introduction of Enhanced Dictation which enables offline use and continuous dictation with live feedback.
Still, this is a system that assumes a live speaker. There is no obviously easy way to route speech from a recorded file through Apple’s Dictation system to produce usable text.
That’s what this post is all about.
You can, in fact, route the speech in an audio file through Apple’s speech-to-text subsystem and render very usable text output. It isn’t intuitive or Apple-easy but it is something that anyone can accomplish with a bit of determination. Here’s how:
The application at the center of this process is Audio HiJack Pro by Rogue Amoeba ($32 USD). There are two things to set up with this app. The first is to identify the source of the audio. It could be any app that emits audio but I used QuickTime Player X. Thus, I set that app as the audio source as follows:

This will capture the audio from anything that this app plays. My sample audio is from NPR and contains a dramatic reading from noted actor, Sam Waterston and looks like this in QuickTime Player X:

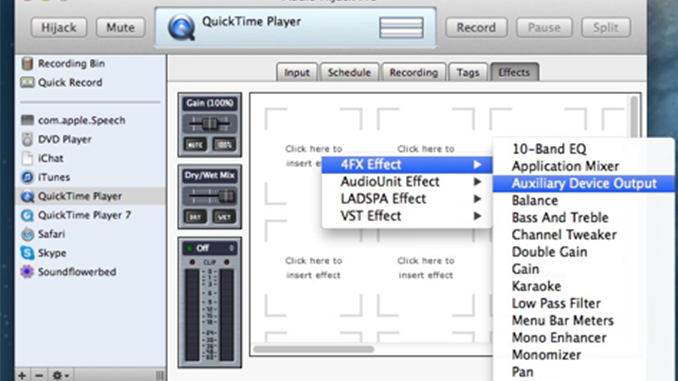
This configuration will grab all the audio from QuickTime Player X as it plays the “NPR Gettsyberg Address” audio file. Next, we use Audio HiJack Pro to send that audio to Soundflower (free). To do that we go to the Effects tab and choose Auxiliary Device Output from the 4FX menu.

The Auxiliary Device Output plug-in enables us to choose the previously installed Soundflower as the recipient of the HiJacked audio as follows:

Once installed, Soundflower becomes an input/output option in your Sound preference pane and everywhere else audio sources and destinations can be specified. In other words, it becomes an integral part of your sound system in MacOS X.
Finally, we set the Dictation input to be Soundflower as follows:

At this point, any audio played by QuickTime Player X will be routed to Soundflower and will thus become available to any application that accepts text input and has a Start Dictation menu item. In Pages, that looks like:

The following screencast illustrates this process from start to finish:
***
Do you have your own solution for this that you’ve been using? Please comment below and share what you’ve learned.
The recent Screenflow upgrade was not in itself a sufficient reason to upgrade to Mavericks, but this neat audio playback>text trick closes the deal…at least for one of my Macs.
That’s brilliant. Thanks for the step by step process!
Wow! Impressive. Very nicely done – Thank you!
Hi. I’ve set up the system to turn audio hijacked by AHJ into dictation which is transcribed to text via Maverick’s Advanced Dictation feature. It is the exact setup described above.
It works perfectly to transcribe text to a TextEdit, Textwrangler or Word document, as long I select Quicktime source in AHJ, click the “Hijack” button, play a QT movie that is on my desktop and immediately click on the TextEdit, Textwrangler or Word window and hit fn, fn. When I hit fn, fn, the audio from my internal speaker cuts out and text is transcribed after a second or two lag. However, if I choose the Hijack source to be either Safari or Chrome, click “Hijack” and then play an embedded video on a website with either the Safari or Chrome browser, nothing is transcribed during the audio cutout period after I click on the TextEdit, Textwrangler or Word window and hit fn, fn. In System Preferences in all cases, sound input is set to internal mic. and sound output is set to internal speakers.
Do you have any suggestions?
To Dr. Frank Lowney:
Your fine outline of how to use Hijack and Soundflower to feed audio files into the Enhanced Dictation system in Apple Mavericks, then into Pages as text, is an process that I think will be useful for some of our needs in managing a live discussion seminar here. We hope to produce editable texts from some of our recorded conversations.
I have installed and linked both Audio Hijack and Soundflower on my new Imac runnning Mavericks, and activated Enhanced Dictation. When I play an MP3 comment recording, I get the sound showing up in the Apple System Preferences Dictation pane (the microphone purple dots bounce). But I am not getting any text to appear in Pages or Word. I may be starting Pages in the wrong way. I have set up Quicktime with the mp3, then started the mp3 playing, then next starting the Pages dictation input with fnfn. The mic bubble shows up in Pages, but no text is produced. I think I must be omitting some obvious step, but I don’t yet know what is disfunctional. Do you have time to give me a clue or 2? I think I have the “Operator Headgap Syndrome.” 😉
Many thanks, Ken Ketner, Peirce Interdisciplinary Professor, Texas Tech University. kenneth.ketner@ttu.edu
Same problem the mic audio wave stops right after i double click the Fn button
Thanks so much for this! Have used Audio Hijack Pro for years but would not have known about the 4FX plugin. 🙂
I’ve been using AHP for years and never had to use a plugin, soundflower is selectable as a destination directly (appears in the select menu next to output device).
I use it with wirecast to add delay to sync up audio (directly in via USB) to the video
I am quite impressed with this system. I tried using the Gettysburg Address MP3 file and it was pretty accurate. The only problem is that it didn’t insert any punctuation. Is that a fixable problem?
Extremely useful information given by you about convert audio to textI would like to say thanks for useful article.
I would really like to be able transcribe audio to text.It is genuinely very useful for me. I like your put up simply because it is very useful for me as effectively.
This great trick has been very useful to me in my job since last summer, every time I need to transcribe recorded presentations. Thank you very much, Dr. Lowney. Unfortunately, after I installed OS X Yosemite last week, I started having problems. The text starts auto-converting in MS Word, as usual, but then after 3 or 4 lines of text it just stops. The dictation icon keeps flashing so I know it still detects sound from the audio file. I had the same problem using TextEdit (it starts converting, then stops after a few lines). It may have something to do with Audio Highjack Pro, which now appears to require an “Extras” program called “Instant On” to integrate with QuickTime. After many hours trying to figure it out, I had to quit and go back to the old fashioned way of transcribing, by starting and stopping the audio player, listening carefully, and typing it out. If anyone comes across a fix, please share. Thank you!
Liz,
I’m having the same problem. After installing Yosemite, the TextEdit transcription stopped working. I’ve read that Audio Hijack does not work with Yoesmite. Frustrating.
When the transcription text stops click MS Words menu bar (not where the text cursor is the the document body). You will see more text keyed into your document. As long as you see the Dictation Mic blinking, you can continue this process. Hope this helps.
Thank you.
I tried VLC player and sound flower and was able to reproduce the same effect. VLC is free as is sound flower. load a video into VLC that you have on your computer. Set dictation in system preferences to sound flower 2ch and in vlc set drop down audio/audio device to sound flower 2ch, open pages and press fn fn if you have not changed that in dictation in system preferences. This is all I had to do to get text from a video. I was also able to take a youtube link click share and copy the shorter quick link and in VLC drop down menu click file/open network and paste the link from youtube. it opens a window in VLC and plays the video. All other settings stay the same.
Hope this helps
Thank you. I tried it and it started working, but after about one page of text it stopped. Maybe it’s a RAM issue with my computer, or my SoundFlower settings. I appreciate your help.
Are you running Yosemite as well? I’m having trouble getting this to work. I’m using an MP3 audio file to convert, but am not getting any text from it.
It’s clear that Soundflower has issues in Yosemite, and since Cycle74 has passed stewardship of Soundflower to RogueAmoeba which in turn appears to be doing nothing with it other than to allow the last version to be available, we need another solution. I have tried using Jack (see and ), which appears to function fine with Yosemite, but I can’t figure out how to get the settings are done properly. It’d be great if Dr. Lowney or someone could give us step-by-step instructions for using Jack to do automated transcription with Apple’s Dictation tool. Thanks very much for your kind consideration.
The problem is not the SoundFlower. In Yosemite, Whenever we try to use the dictation feature in OSX it mutes other sounds and active only the build-in microfone. You need to set some hidden preferences to make this work. Open Terminal and enter the two commands below:
defaults write com.apple.SpeechRecognitionCore AllowAudioDucking -bool NO
defaults write com.apple.speech.recognition.AppleSpeechRecognition.prefs DictationIMAllowAudioDucking -bool NO
After doing this turn off dictation in Systems Preferences, wait a few seconds and then re-enable it. You should now be able to dictate while audio is playing. I’ve only tried this while using a headset/headphones, it’s probably not advisable without. 🙂
To restore your system to it’s virginal state, run these commands in Terminal and then restart dictation:
defaults delete com.apple.SpeechRecognitionCore AllowAudioDucking
defaults delete com.apple.speech.recognition.AppleSpeechRecognition.prefs DictationIMAllowAudioDucking
I prefer to user WavTap than SoundFlower… with WavTap is possible listen and dictate at same time. WavTap is an application that permit to record all audio playing to an .wav file. Install WavTap, than config the dictation to get audio from WavTap virtual device, than start the WavTap app, and than start to dictate. Is note necessary to record the audio, only start WavTap app.
WavTap can be found here:
https://github.com/pje/WavTap
Ooops, those links for Jack didn’t show in the above post, so let me see if this works: http://www.jackosx.com and jackaudio.org
The problem is not the SoundFlower. In Yosemite, Whenever we try to use the dictation feature in OSX it mutes other sounds and active only the build-in microfone. You need to set some hidden preferences to make this work. Open Terminal and enter the two commands below:
defaults write com.apple.SpeechRecognitionCore AllowAudioDucking -bool NO
defaults write com.apple.speech.recognition.AppleSpeechRecognition.prefs DictationIMAllowAudioDucking -bool NO
After doing this turn off dictation in Systems Preferences, wait a few seconds and then re-enable it. You should now be able to dictate while audio is playing. I’ve only tried this while using a headset/headphones, it’s probably not advisable without. 🙂
To restore your system to it’s virginal state, run these commands in Terminal and then restart dictation:
defaults delete com.apple.SpeechRecognitionCore AllowAudioDucking
defaults delete com.apple.speech.recognition.AppleSpeechRecognition.prefs DictationIMAllowAudioDucking
It worked for me, thanks!
I prefer to user WavTap than SoundFlower… with WavTap is possible listen and dictate at same time. WavTap is an application that permit to record all audio playing to an .wav file. Install WavTap, than config the dictation to get audio from WavTap virtual device, than start the WavTap app, and than start to dictate. Is note necessary to record the audio, only start WavTap app.
WavTap can be found here:
https://github.com/pje/WavTap
First off, thanks for this great tutorial! My father is wanting to “write” his memoirs but is computer-challenged, and I think recording his memoirs is the only hope of it getting done. With luck, your procedure will help us get them into text.
But after initial tests, I’m having an odd problem: Occasionally the line of transcribed text just disappears!
My ignorant theory is that some noise or pop in the audio is causing a reset, but noise suppression doesn’t seem to help.
Does anyone have any ideas?
Just a quick note to let everyone know that I have re-tested this technique under macOS 10.12.x and can report that it still works as described. However, there are some new developments to account for as follows:
1) Soundflower is now back in the hands of the original developer who has released version 2.0b2 which is essential for macOS 10.12 and this STT process.
2) It is now possible for Dictation in Accessibility to conflict with this technique if the file contains a word that sounds like a speech command. This can be countered by setting a “dictation keyword” phrase that is not likely to appear in the audio file you are transcribing. I use the word “Shazam” and that works well for me. I also de-select “Enable advanced commands” to reduce the potential number of triggers that would stop the process. This may not be strictly necessary with the keyword in place.
3) Dictation no longer has a pane of its own in macOS 10.12. It is now a tab in the Keyboard pane.
I should also emphasize the importance of selecting Enhanced Dictation and producing an audio file that is clean with clear enunciation by the speaker.
Thanks Frank!
One more thing: Audio Hijack no longer requires adding 4DX. That’s all built-in now.
Hello Dr. Frank Lowney,
I was wondering if this also would work for a OS X Yosemite version 10.10.5?
Thank you in advance for your reply.
Since this post originally used Mac OS X 10.9, and Frank recently posted that it still works on Mac OS X 10.12 (with a few changes), we would think it should work on Mac OS X 10.10, but we haven’t tested this ourselves on that OS.
That’s great, thanks Frank, and I’m sure many frustrated users will be very grateful for what you have shared!
But what about the large (and growing) number of us who cannot afford the latest couple of versions of Mac OS and are currently confined to running older versions? My Mac OS was the last one before Mac’s dictation came in, and cannot run Quicktime X either.
If I could have later OS, I would have already figured out years ago how to get large files (an hour or more) of recorded audio into text. I have tried patching through my external speakers to the microphone into Dragon Dictate but it can’t pick up the words via that indirect route. I need a software that is broader in application than just a few versions of Mac OS…. do you know of anything?
Is there a place that has these sequential steps for using Audio Hijack from a QuickTime application and sending text to Sunflower? 6/24/2017
Tried on mac os 10.13.3 and it works but then stops after a page of text. Any ideas?
Was able to do it with macOS High Sierra and the latest Audio Hijack software. Not 100% perfect but pretty good! Thanks so much for the help. Please ignore my earlier post on not being able to do it.